
This blog chapter is now about the different components that build the cluster
This solution is also used by SUSE and Redhat in their products:
https://www.suse.com/products/highavailability/
https://www.redhat.com/en/store/high-availability-add#?sku=RH00025
JWB-Systems can deliver you training and consulting on all kinds of Pacemaker clusters:
SLE321v15 Deploying and Administering SUSE Linux Enterprise High Availability 15
SLE321v12 Deploying and Administering SUSE Linux Enterprise High Availability 12
RHEL 8 / CentOS 8 High Availability
RHEL 7 / CentOS 7 High Availability
Now after our Cluster us up and running (but still without providing services) we need to talk about how the Cluster works.
For this purpose we use this diagram:
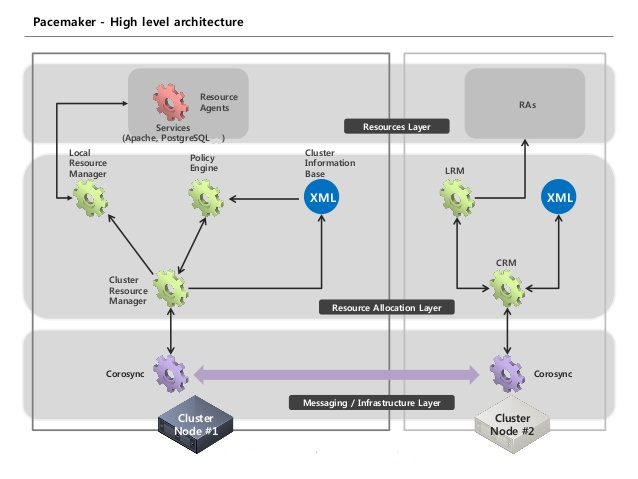
We have 3 different layers in the cluster:
- Messaging / Infrastructure
- Resource Allocation
- Resources
Let’s have a closer look at them.
Messaging / Infrastructure Layer
In this layer Corosync is running. It’s running as a process on every cluster node, startet and managed by systemd.
Every communication regarding the Cluster is done in this layer: If the Cluster Resource Manager (to be explained soon) from node1 wants to talk to the Cluster Resource Manager of node2 it must be done via corosync.
The configuration of this layer is done the classical linux way; just by config files on each node, residing at /etc7corosync/ .
Resource Allocation Layer
This layer is the clusters brain: here all the decisions where to start, stop and monitor a resource will be done.
We have on every node several processes running in this layer:
Cluster Resource Manager
The Cluster Resource Manager will be further shortened as CRM.
It is is the executive instance in the cluster. It runs on every node, but only on one node i has the role “Designated Coordinator” (shortened DC). When you fire up the cluster and all nodes begin to communicate with each other, one node is elected as DC. He is responsible for reaching and maintaining a consistent state in the cluster.
Policy Engine
Runs on every node and is the helper of the CRM. Everytime the cluster is in an inconsistent state, the crmd with role DC asks his local policy engine:
Please calculate for me all steps that need to be executed to bring the cluster again in a consistent state.
The policy engine is then calculating all necessary steps based on the actual state of the cluster and the “Should-be”-state of the cluster (both stored in the Cluster information Base) and then sending them back to the local CRM.
Local Resource Manager
The Local Resource Manager will be further shortened as LRM
It runs on every node and has the local authority about resources running on this node.
If the CRM in DC role on node1 is deciding that its necessary to start the apache resource on node2, then he is communicating that to the CRM on node2 via corosync.
The CRM on node2 is then communicating with the LRM on node2 and telling him: start apache2. The LRM is the executing the Resource Agent for apache with the parameter “start”.
Cluster Information Base
The Cluster Information Base will be further shortened as CIB.
Its a replicated xml based database that stores the cluster configuration (parameters for the general cluster behaviour, configured resources, and constraints that define where to start and stop resources). But it stores also the actual cluster state.
The CIB on the node that is elected as DC has the master copy of the CIB. Changes in the CIB will be immediately replicated to all CIB’s on the other nodes in the cluster.
If a change cannot be replicated to all actual members of the cluster it will be rolled back.
If the node that is DC is failing, the remaining nodes immediately elect an new Designated Coordinator. This is possible because all nodes have always an actual copy of the CIB.
If you are changing the cluster configuration , for example by adding a new resource, the information is stored and replicated in the CIB.
Resources Layer
The third and highest layer we have in the cluster is the Resource Layer.
Here we find our so called resource agents. They are simply scripts (but can also be binarys) that must understand minimum some parameters: start, stop, monitor.
The LRM from the resource allocation layer is executing this resource agents always with the parameter so that the resource agent knows what he has to do.
Example: The CRM in role DC (here on node1) decides that apache need to be stopped on node1 and started on node2
The so he calls the LRM on node1 and tells him to stop the apache resource. The LRM in now opening a sub-shell and executing the apache resource agent with the parameter stop.
The resource agent needs to report back to the LRM with the exit code 0 for a successful execution of the task. The lrmd is reporting that back to the CRM in role DC.
The this CRM (DC) is calling the CRM on node2 to to start the apache resource there. The CRM on node2 is then calling his local LRM, and this LRM is then executing the apache resource agent in a sub-shell with the parameter start. Again a successful start must be reported back to the CRM (DC).
The cluster strongly relies on this reporting back of results from operations. There are timeouts also for such operations, if they are not reported back in time successful or unsuccessful, they are considered automatically as unsuccessful.
This timeouts are usually configured globally in the cluster, but also altered on a per resource/operations basis.
If a start operation for a resource fails then the resources failcount to that node is set automatically to maximum and the resource cannot be started on this node until the failcount is reseted.
If a monitor operation fails the cluster is trying to restart the resource and counting up 1 the failcount of this resource to this node.
If a stop operation fails things get worse: The cluster cannot absolute surely know what the status of the stopped resource is: Maybe it’s still running?
The default behaviour for such a situation is then: the cluster needs to make sure that the resource is really stopped. The only way he can do that is by hard reseting (STONITH) this node!
After the STONITH is confirmed the cluster can go on doing his work and start the resource maybe on another node.
In the next part we talk about Resources and how to configure them in the cluster.
CU soon here 🙂